Lectores, en esta ocasión les traigo otro "Como" para quienes administran bases de datos en el gestor MySQL (posiblemente aplique para MariaDB pero no he probado).
La replicación es una técnica donde a una base de datos se le indica ser copiada uno o mas destinos. Por lo que la fiabilidad, tolerancia a fallos o accesibilidad de la base de datos se puede mejorar.
Las replicaciones pueden darse:
La replicación de MySQL es considerada como base transaccional. Para implementar la replicación en MySQL, el servicio maestro guarda un log de transacciones de todas las actualizaciones que ha realizado.
Los servicios esclavos, se conectan al maestro y leen el log y actualizan cada registro. Además de mantener un log de transacciones, el maestro lleva a cabo diversas tareas de mantenimiento, como la rotación de registro y control de acceso.
Cuando se producen nuevas transacciones y el servicio maestro, actualiza el log, los servicios esclavos realizan las mismas transacciones en su copia del servicio maestro y actualizan su posición.
Este proceso de replicación maestro-esclavo se realiza de forma asíncrona, lo que significa que el servicio maestro no tiene que esperar a que los esclavos se pongan al día.
Si los esclavos no pueden conectar con el maestro por un período de tiempo, se descarga y ejecuta todas las transacciones pendientes cuando se restablezca la conectividad.
La replicación de bases de datos permite tener una copia exacta de una base de datos en vivo de un servidor maestro en otro servidor remoto (servidor esclavo) sin tener que desconectar el servidor maestro.
En caso de que el servicio principal este inactivo o tenga algún problema, se puede señalar temporalmente clientes de bases de datos o de resolución de DNS para la dirección IP del servicio esclavo, logrando un failover transparente.
Se debe señalar que la replicación de MySQL no es una solución de copia de seguridad. Por ejemplo, si un comando DELETE no deseado es ejecutado en el servicio maestro por accidente, la misma transacción se aplicara en todos los servicios esclavos.
Se estará mostrando como realizar la replicación de MySQL en dos equipos Linux. Para este ejemplo se tomaran las direcciones IP 192.168.2.1 y 192.168.2.2 para servicio maestro y esclavo respectivamente.
Primero, acceder a la consola de MySQL y crear la base de datos test_repl
Posterior crear una tabla dentro de la base de datos e insertar 3 registros de ejemplo:
Posterior de salir de la consola de MySQL, editar el archivo my.cnf utilizando su editor favorito, el archivo puede encontrarse en /etc o en /etc/mysql.
Agregar las siguientes lineas
La opción server-id asigna un ID entero (en el rango de 1 a 2^32) al servidor master. Para temas de ejemplo, el ID 1 y 2 seran asignados para el servidor master y esclavo respectivamente.
El servidor master debe tener activo en logging binario (con la opción log-bin) el cual activara la replicación. Asignar a la opción binlog-do-db el nombre de la base de datos que replicara al servidor esclavo.
Las opciones innodb_flush_log_at_trx_comming = 1 y sync_binlog=1deben estar activo para una mejor posibilidad de durabilidad y consistencia en la replicación.
Posterior a guardar los cambios en el archivo my.cnf, reiniciar el servicio mysqld.
Posterior, entrar a la consola del servidor master para crear un nuevo usuario para el servidor esclavo. Asignar el permiso de replicación al usuario creado.
El usuario creado (en este ejemplo) es repl_user y la contraseña es repl_user_password. Confirmar que el servidor MySQL master no este asignado a la interfaz looback, es decir, que escuche peticiones solo en la dirección local del servidor, ya que el servidor esclavo necesita registrarse al servidor master vía su dirección IP.
Finalmente, revisar en el servidor master su estado ejecutando el siguiente comando en la consola:

Nótese que la primera y la segunda columna será utilizada por el servidor esclavo para realizar la replicación.
Ahora es el turno del servidor esclavo. Primero editar el archivo my.cnf con el editor favorito y agregar las siguientes lineas dejo de la sección [mysqld].
Posterior, guardar los cambios y reiniciar el servicio.
Entrar a la consola del servidor esclavo y ejecutar los siguientes comandos
Con el comando anterior el servicio MySQL local se convierte en servidor esclavo para el servidor master en 192.168.2.1. Entonces el servidor esclavo se conecta al servidor master con el usuario repl_user y monitorea el archivo log binario master-bin.000002 para la replicación.

La imagen anterior muestra el estado del servidor esclavo. Para confirmar que la replicación se ha realizado, revisar los 3 campos marcados de la salida del comando de estado.
Primero, el dato Master_Host debe mostrar la dirección IP del servidor maestro. Segundo, el dato Master_User indica el usuario utilizado para la replicación. Y tercero el dato Slave_IO_Running debe mostrar el valor 'Yes'
Cuando el servidor esclavo comienza a trabajar, este leerá automáticamente el log de la base de datos del servidor maestro y creara las mismas tablas y entradas en caso que no se encuentren el servido esclavo.
Con lo anterior quedaría configurada la replicación entre ambos servidores. Esperando que sea de utilidad a mas de alguno.
Saludos y nos leemos en una próxima entrada.
Introducción
La replicación es una técnica donde a una base de datos se le indica ser copiada uno o mas destinos. Por lo que la fiabilidad, tolerancia a fallos o accesibilidad de la base de datos se puede mejorar.
Las replicaciones pueden darse:
- Basado en instantánea de la base (snapshot), donde la base de datos completa es copiada a otro equipo.
- Basado en combinación o fusión, donde dos o mas bases se copian y se unen en una sola.
- Basado en transacción, donde la actualización de los datos se aplican periódicamente entre un servicio maestro y uno esclavo.
La replicación de MySQL es considerada como base transaccional. Para implementar la replicación en MySQL, el servicio maestro guarda un log de transacciones de todas las actualizaciones que ha realizado.
Los servicios esclavos, se conectan al maestro y leen el log y actualizan cada registro. Además de mantener un log de transacciones, el maestro lleva a cabo diversas tareas de mantenimiento, como la rotación de registro y control de acceso.
Cuando se producen nuevas transacciones y el servicio maestro, actualiza el log, los servicios esclavos realizan las mismas transacciones en su copia del servicio maestro y actualizan su posición.
Este proceso de replicación maestro-esclavo se realiza de forma asíncrona, lo que significa que el servicio maestro no tiene que esperar a que los esclavos se pongan al día.
Si los esclavos no pueden conectar con el maestro por un período de tiempo, se descarga y ejecuta todas las transacciones pendientes cuando se restablezca la conectividad.
En caso de que el servicio principal este inactivo o tenga algún problema, se puede señalar temporalmente clientes de bases de datos o de resolución de DNS para la dirección IP del servicio esclavo, logrando un failover transparente.
Se debe señalar que la replicación de MySQL no es una solución de copia de seguridad. Por ejemplo, si un comando DELETE no deseado es ejecutado en el servicio maestro por accidente, la misma transacción se aplicara en todos los servicios esclavos.
Se estará mostrando como realizar la replicación de MySQL en dos equipos Linux. Para este ejemplo se tomaran las direcciones IP 192.168.2.1 y 192.168.2.2 para servicio maestro y esclavo respectivamente.
Configurando el servicio maestro
Primero, acceder a la consola de MySQL y crear la base de datos test_repl
$ mysql -u root -p
mysql> CREATE DATABASE test_repl;
Posterior crear una tabla dentro de la base de datos e insertar 3 registros de ejemplo:
mysql> USE test_repl;
mysql> CREATE TABLE employee (
-> EmployeeID int,
-> LastName varchar(255),
-> FirstName varchar(255),
-> Address varchar(255),
-> City varchar(255));
mysql> INSERT INTO employee VALUES(1,"LastName1","FirstName1","Address1","City1"),
-> (2,"Lastname2","FirstName2","Address2","City2"),
-> (3,"LastName3","FirstName3","Address3","City4");
Posterior de salir de la consola de MySQL, editar el archivo my.cnf utilizando su editor favorito, el archivo puede encontrarse en /etc o en /etc/mysql.
Agregar las siguientes lineas
[mysqld]
server-id=1
log-bin=master-bin.log
binlog-do-db=test_repl
innodb_flush_log_at_trx_commit=1
sync_binlog=1
La opción server-id asigna un ID entero (en el rango de 1 a 2^32) al servidor master. Para temas de ejemplo, el ID 1 y 2 seran asignados para el servidor master y esclavo respectivamente.
El servidor master debe tener activo en logging binario (con la opción log-bin) el cual activara la replicación. Asignar a la opción binlog-do-db el nombre de la base de datos que replicara al servidor esclavo.
Las opciones innodb_flush_log_at_trx_comming = 1 y sync_binlog=1deben estar activo para una mejor posibilidad de durabilidad y consistencia en la replicación.
Posterior a guardar los cambios en el archivo my.cnf, reiniciar el servicio mysqld.
# systemctl restart mysqld
o con el comando# /etc/init.d/mysqld restart
Posterior, entrar a la consola del servidor master para crear un nuevo usuario para el servidor esclavo. Asignar el permiso de replicación al usuario creado.
mysql> CREATE USER repl_user@192.168.2.2;
mysql> GRANT REPLICATION SLAVE ON *.* TO repl_user@192.168.2.2 IDENTIFY BY 'repl_user_password';
mysql> FLUSH PRIVILEGES;
El usuario creado (en este ejemplo) es repl_user y la contraseña es repl_user_password. Confirmar que el servidor MySQL master no este asignado a la interfaz looback, es decir, que escuche peticiones solo en la dirección local del servidor, ya que el servidor esclavo necesita registrarse al servidor master vía su dirección IP.
Finalmente, revisar en el servidor master su estado ejecutando el siguiente comando en la consola:
mysql> SHOW MASTER STATUS;

Nótese que la primera y la segunda columna será utilizada por el servidor esclavo para realizar la replicación.
Configurando el servicio esclavo
Ahora es el turno del servidor esclavo. Primero editar el archivo my.cnf con el editor favorito y agregar las siguientes lineas dejo de la sección [mysqld].
server-id = 2
master-host = 192.168.2.1
master-connect-retry = 60
master-user = repl_user
master-password = repluser
master-info-file = mysql-master.info
relay-log-index = /var/lib/mysql/slave-relay-bin.index
relay-log-info-file = /var/lib/mysql/mysql-relay-log.info
relay-log = /var/lib/mysql/slave-relay-bin
log-error = /var/lib/mysql/mysql.err
log-bin = /var/lib/mysql/slave-bin
Posterior, guardar los cambios y reiniciar el servicio.
# systemctl restart mysqld
mysql> CHANGE MASTER TO MASTER_HOST='192.168.2.1', MASTER_USER='repl_user',
-> MASTER_PASSWORD='repl_user_password', MASTER_LOG_FILE='master-bin.00002',
-> MASTER_LOG_POS=107;
mysql> SLAVE START;
mysql> SHOW SLAVE STATUS \G;
Con el comando anterior el servicio MySQL local se convierte en servidor esclavo para el servidor master en 192.168.2.1. Entonces el servidor esclavo se conecta al servidor master con el usuario repl_user y monitorea el archivo log binario master-bin.000002 para la replicación.
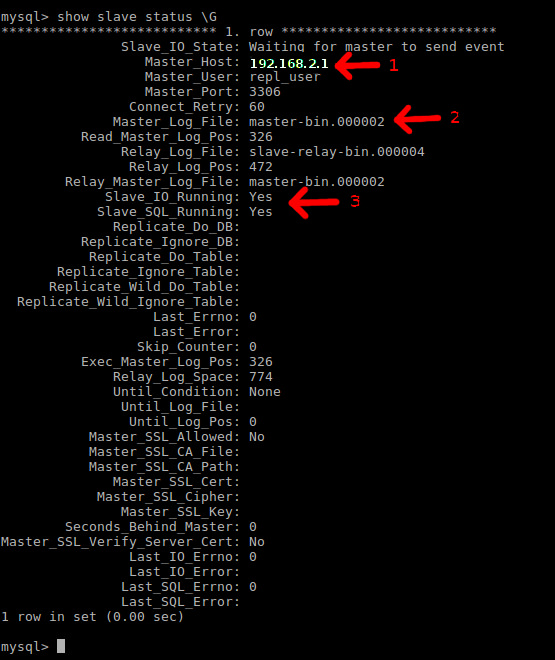
La imagen anterior muestra el estado del servidor esclavo. Para confirmar que la replicación se ha realizado, revisar los 3 campos marcados de la salida del comando de estado.
Primero, el dato Master_Host debe mostrar la dirección IP del servidor maestro. Segundo, el dato Master_User indica el usuario utilizado para la replicación. Y tercero el dato Slave_IO_Running debe mostrar el valor 'Yes'
Cuando el servidor esclavo comienza a trabajar, este leerá automáticamente el log de la base de datos del servidor maestro y creara las mismas tablas y entradas en caso que no se encuentren el servido esclavo.
Con lo anterior quedaría configurada la replicación entre ambos servidores. Esperando que sea de utilidad a mas de alguno.
Saludos y nos leemos en una próxima entrada.
Comentarios
Publicar un comentario
Son bienvenidos tus comentarios, solo se respetuoso. Saludos